チェックポイント
Create a Cloud Storage bucket
/ 50
Initialize Cloud Dataprep
/ 50
Dataprep: Qwik Start
このラボは Google のパートナーである Trifacta と共同開発されました。アカウント プロフィールでサービスの最新情報、お知らせ、特典の受け取りをご希望になった場合、お客様の個人情報が本ラボのスポンサーである Trifacta と共有される場合があります。
GSP105

概要
Cloud Dataprep by Trifacta は、分析用データの可視的な探索、クリーニング、準備を行うインテリジェントなデータサービスです。Cloud Dataprep はサーバーレスで、どのような規模でも稼働します。インフラストラクチャのデプロイや管理は必要ありません。コードも不要で、クリックするだけで簡単にデータを準備できます。
このラボでは Dataprep を使って、データセットのインポート、不一致データの修正、データの変換と結合を行います。初めてご利用の場合でも、ラボの終了時にはすべての操作を行えるようになります。
設定と要件
[ラボを開始] ボタンをクリックする前に
こちらの手順をお読みください。ラボの時間は記録されており、一時停止することはできません。[ラボを開始] をクリックするとスタートするタイマーは、Google Cloud のリソースを利用できる時間を示しています。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
- 標準的なインターネット ブラウザ(Chrome を推奨)
- ラボを完了するために十分な時間を確保してください。ラボをいったん開始すると一時停止することはできません。
ラボを開始して Google Cloud コンソールにログインする方法
-
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側の [ラボの詳細] パネルには、以下が表示されます。
- [Google コンソールを開く] ボタン
- 残り時間
- このラボで使用する必要がある一時的な認証情報
- このラボを行うために必要なその他の情報(ある場合)
-
[Google コンソールを開く] をクリックします。 ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択] ダイアログが表示されたら、[別のアカウントを使用] をクリックします。 -
必要に応じて、[ラボの詳細] パネルから [ユーザー名] をコピーして [ログイン] ダイアログに貼り付けます。[次へ] をクリックします。
-
[ラボの詳細] パネルから [パスワード] をコピーして [ようこそ] ダイアログに貼り付けます。[次へ] をクリックします。
重要: 認証情報は左側のパネルに表示されたものを使用してください。Google Cloud Skills Boost の認証情報は使用しないでください。 注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。 -
その後次のように進みます。
- 利用規約に同意してください。
- 一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
- 無料トライアルには登録しないでください。
その後このタブで Cloud Console が開きます。

タスク 1. プロジェクトに Cloud Storage バケットを作成する
-
Cloud コンソールで、ナビゲーション メニュー(
) > [Cloud Storage] > [バケット] の順に選択します。
-
[バケットを作成] をクリックします。
-
[バケットを作成] ダイアログの [名前] で、バケットに一意の名前を付けます。他の設定はデフォルト値のままにします。
-
[
オブジェクトへのアクセスを制御する方法を選択する] で、[このバケットに対する公開アクセス禁止を適用する] チェックボックスをオフにします。 -
[作成] をクリックします。
これでバケットが作成されました。後の手順で使用するため、バケット名をメモしておきます。
完了したタスクをテストする
[進行状況を確認] をクリックして、実行したタスクを確認します。Cloud Storage バケットが正常に作成されている場合は、評価スコアが表示されます。
タスク 2. Cloud Dataprep を初期化する
- ナビゲーション メニュー > [Dataprep] の順に選択します。
- チェックボックスをオンにして Google Dataprep の利用規約に同意し、[同意する] をクリックします。
- チェックボックスをオンにしてアカウント情報を Trifacta と共有することに同意し、[同意して続行] をクリックします。
- [許可] をクリックして、Trifacta がプロジェクトのデータにアクセスすることを許可します。
- 受講生のユーザー名をクリックして、Cloud Dataprep by Trifacta にログインします。使用するユーザー名は、ラボの左側のパネルの [Username] に示されています。
- [許可] をクリックして、Google Cloud ラボアカウントに Cloud Dataprep へのアクセスを許可します。
- チェックボックスをオンにし、[Accept] をクリックして Trifacta の利用規約に同意します。
- [First time set up] 画面で [Continue] をクリックして、デフォルトのストレージの場所を作成します。
Dataprep が開きます。
完了したタスクをテストする
[進行状況を確認] をクリックして、実行したタスクを確認します。Cloud Dataprep がデフォルトのストレージの場所で正常に初期化されている場合は、評価スコアが表示されます。
タスク 3. フローを作成する
Cloud Dataprep では、flow ワークスペースを使用してデータセットにアクセスし、操作します。
- フローアイコンをクリックし、[Create] ボタンをクリックして [Blank Flow] を選択します。
![フローアイコン、[Create] ボタン、[Blank Flow] オプション](https://cdn.qwiklabs.com/YG1phM5jiQwM1RCHHoMDFd1agP2BHKRlkYlebPFq0YY%3D)
- [Untitled Flow] をクリックし、フローの名前と説明を入力します。このラボでは米国連邦選挙委員会 2016 のデータを使用するため、[Flow Name] に「FEC-2016」、[Flow Description] に「米国連邦選挙委員会 2016」と入力します。
- [OK] をクリックします。
FEC-2016 フローのページが表示されます。
タスク 4. データセットをインポートする
このセクションでは、データをインポートして FEC-2016 フローに追加します。
-
[Add Datasets] をクリックし、[Import Datasets] リンクを選択します。
-
Cloud Storage からデータセットをインポートするため、左側のメニューペインで [Cloud Storage] を選択します。次に、鉛筆アイコンをクリックしてファイルのパスを編集します。
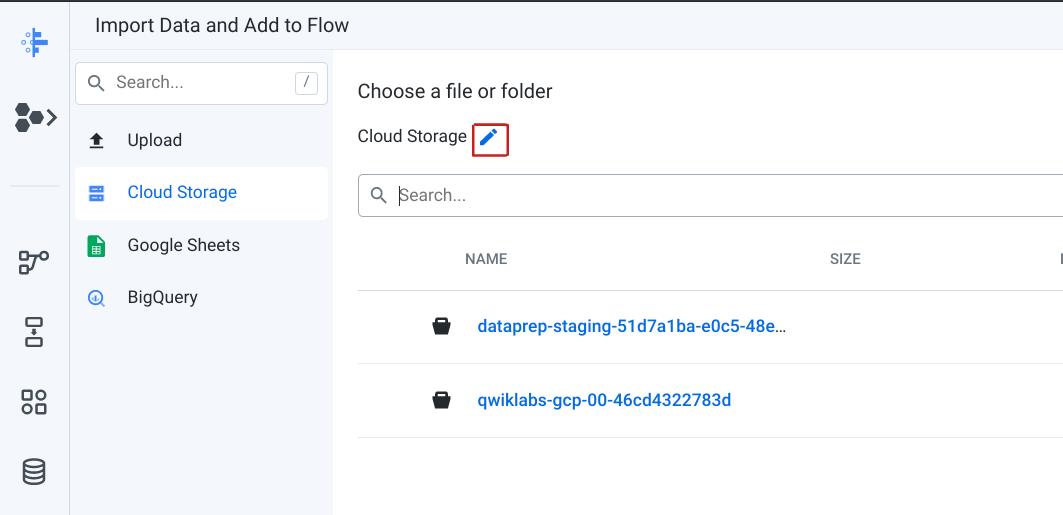
- [Choose a file or folder] テキスト ボックスに「
gs://spls/gsp105」と入力して、[Go] をクリックします。
[Go] と [Cancel] のボタンが表示されるように、必要に応じてブラウザ ウィンドウを広げてください。
-
[us-fec/] をクリックします。
-
cn-2016.txtの横にある + アイコンをクリックすると、データセットが作成されて右側のペインに表示されます。右側のペインにあるデータセットのタイトルをクリックして、名前を「Candidate Master 2016」に変更します。 -
同様に、
itcont-2016-orig.txtのデータセットを追加し、名前を「Campaign Contributions 2016」に変更します。 -
両方のデータセットが右側のペインに表示されたら、[Import & Add to Flow] をクリックします。
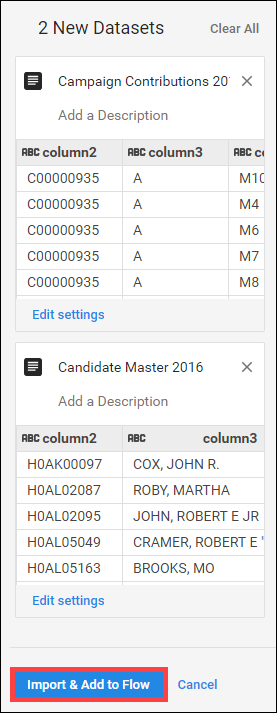
2 つのデータセットがフローとして表示されます。
タスク 5. 候補者ファイルを準備する
- デフォルトで、[Candidate Master 2016] データセットが選択されています。右側のペインで、[Edit Recipe] をクリックします。
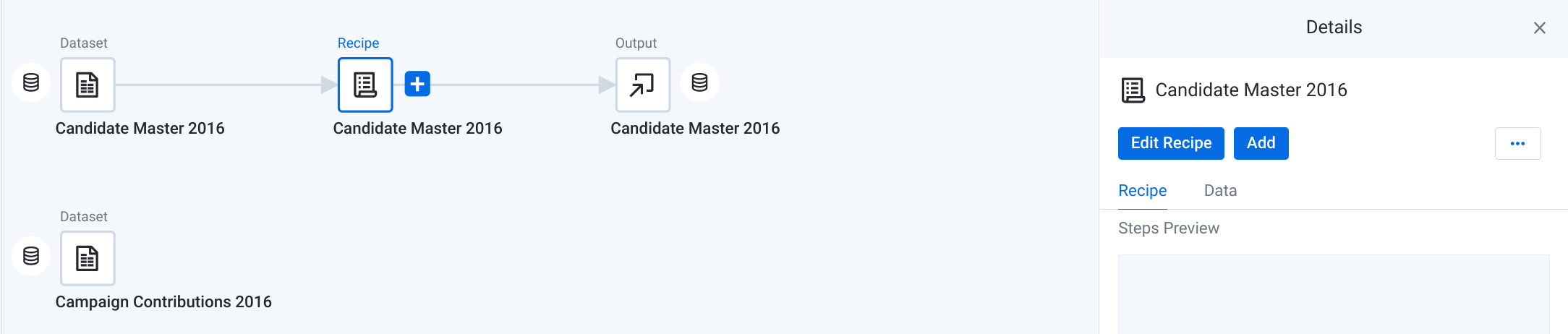
[Candidate Master 2016] Transformer ページがグリッドビューで開きます。
![グリッドビューの [Candidate Master 2016] Transformer ページ](https://cdn.qwiklabs.com/9r2CStT1fxAbpxqs3CH7XWPY5OjUL5%2F63C3HL21TBNo%3D)
Transformer ページでは、変換レシピを作成して、サンプルに適用した結果を確認できます。表示内容に問題がなければ、データセットに対してジョブを実行します。
- 各列の見出しには、データ型を示す名前と値があります。データ型を表示するには、列のアイコンをクリックします。
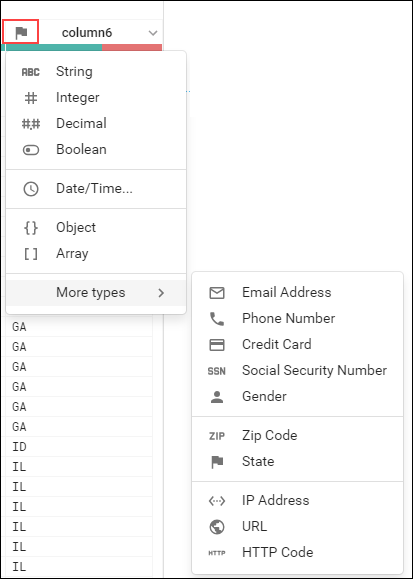
-
列の名前をクリックすると、右側に [Details] パネルが開きます。
-
[Details] パネルの右上にある [X] をクリックして、[Details] パネルを閉じます。
以下の手順では、グリッドビューでデータを探索し、レシピに変換ステップを適用します。
- column5 には 1990~2064 年のデータがあります。スプレッドシートで行うように [column5] の幅を広げると、年ごとにデータが分かれます。最も背の高いビン(2016 年)をクリックして選択します。
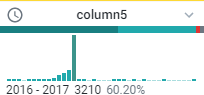
すると、これらの値が選択されたステップが作成されます。
- 右側の [Suggestions] パネルの [Keep rows] セクションで [Add] をクリックし、このステップをレシピに追加します。
![[Suggestions] パネル](https://cdn.qwiklabs.com/Ts1eNo7vDLqRv%2FjotrG8%2FK8kHycDUYORiuFK%2F5xTkp4%3D)
右側のレシピパネルに次のステップが追加されます。
Keep rows where(DATE(2016, 1, 1) <= column5) && (column5 < DATE(2018, 1, 1))
- column6(State)で、ヘッダーの不一致(赤色)部分にカーソルを合わせてクリックし、不一致の行を選択します。
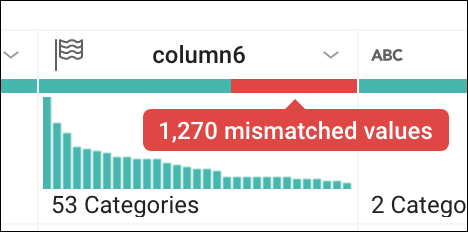
下にスクロールして(赤でハイライト表示されています)不一致の値を見つけます。ほとんどのレコードで、column7 の値は「P」、column6 の値は「US」になっていることがわかります。不一致が発生するのは、column6 が「State」列(旗のアイコンで示される)としてマークされている一方で、State 以外(「US」など)の値があるからです。
- 不一致を修正するには、[Suggestions] パネルの上部にある [X] をクリックして変換をキャンセルし、column6 の旗のアイコンをクリックして String 列に変更します。
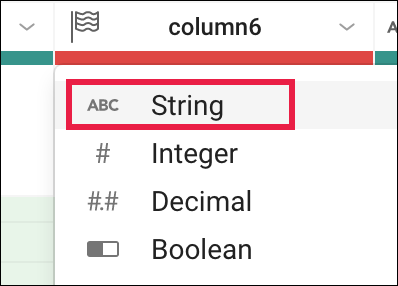
これで不一致がなくなり、列マーカーが緑色になります。
- 大統領候補者のみになるようにフィルタします。column7 の値が「P」のレコードが大統領候補者です。column7 のヒストグラムで 2 つのビンにカーソルを合わせ、どちらが「H」でどちらが「P」かを確認します。「P」のビンをクリックします。
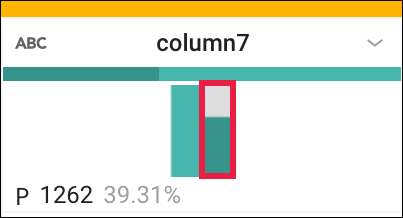
- 右側の [Suggestions] パネルで [Add] をクリックして、このステップをレシピに受け入れます。
![[Keep rows] ボックス](https://cdn.qwiklabs.com/3rctj2B3qPP53yr4UU4raLXyed9Zk8lHPlaXNNsZmhY%3D)
タスク 6. Contributions ファイルをラングリングして Candidates ファイルに結合する
結合ページでは、現在のデータセットを別のデータセットまたはレシピに追加できます。この処理は両方のデータセットに共通する情報に基づいて行われます。
Contributions ファイルを Candidates ファイルに結合するには、まず Contributions ファイルをクリーンアップします。
- グリッドビューページの上部で [FEC-2016](データセット セレクタ)をクリックします。
![グリッドビュー ページの上部にある [FEC-2016]](https://cdn.qwiklabs.com/HjbiWzAPc2RlYFro3r4llT65MBJjJkcA%2FklDCnLHn%2BU%3D)
-
グレー表示の [Campaign Contributions 2016] をクリックして選択します。
-
右側のペインで [Add] > [Recipe] をクリックし、[Edit Recipe] をクリックします。
-
ページの右上にあるレシピアイコンをクリックし、[Add New Step] をクリックします。
![レシピアイコンと [Add New Step] ボタン](https://cdn.qwiklabs.com/RSjdCHmcco6eqx2PxMao6QLRwsGdN17OuuKWuKScdJA%3D)
データセット内の余分な区切り文字を削除します。
- 検索ボックスに次の Wrangle 言語のコマンドを入力します。
Transformation Builder により Wrangle コマンドが解析され、検索と置換の変換フィールドにデータが入力されます。
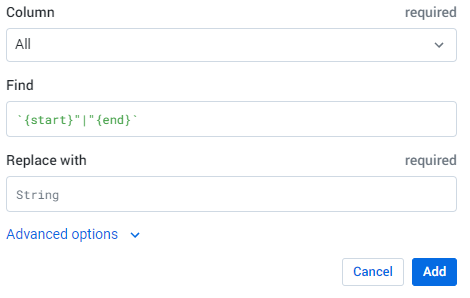
-
[Add] をクリックして、変換をレシピに追加します。
-
新しいステップをもう 1 つレシピに追加します。[New Step] をクリックし、検索ボックスに「Join」と入力します。
![[Search transformations] ボックス](https://cdn.qwiklabs.com/R0Fk6rYEUC7dlUnXULpsr4UXwyI38nKt9koliI%2BmVeo%3D)
-
[Join datasets] をクリックして結合のページを開きます。
-
Campaign Contributions 2016 と結合する [Candidate Master 2016] をクリックして、右下の [Accept] をクリックします。

- 右側の [Join keys] セクションにカーソルを合わせ、鉛筆(編集)アイコンをクリックします。
![[Join conditions] ボックス](https://cdn.qwiklabs.com/H4yPICUZhn0v03sH8lME2m%2FOnPRm2EK28AYf1CqwWK0%3D)
共通のキーが推定された後、多くの共通値が結合キーとして提案されます。
- [Add Key] パネルの [Suggested join keys] セクションで、[column2 = column11] をクリックします。
![[Add Key] パネル](https://cdn.qwiklabs.com/PVJawQJsD8zidQznUENkTaUpglQkmkZUoOe8n7dDMmE%3D)
- [Save and Continue] をクリックします。
column2 と column11 が確認用に開きます。
- [Next] をクリックし、[Column] ラベルの左側のチェックボックスをオンにします。これにより、両方のデータセットのすべての列が、結合されるデータセットに追加されます。
![[Column] ラベルのリスト](https://cdn.qwiklabs.com/Y0yG7pQbqD9xQ%2FaaawSVMTCspoeJ3GlWrllws8dNzZ0%3D)
- [Review] をクリックし、[Add to Recipe] をクリックしてグリッドビューに戻ります。
タスク 7. データのサマリー
column 16 の献金を集計、平均化、カウントし、column 2、24、8 の ID、名前、所属政党別に候補者をグループ化して、有用なサマリーを生成します。
- 右側のレシピパネルの上部にある [New Step] をクリックし、[Transformation] 検索ボックスに次の式を入力して、集計データをプレビューします。
結合された集計データの初期サンプルが表示されます。これは、米国大統領候補と 2016 年の選挙献金指標のサマリー テーブルを表します。
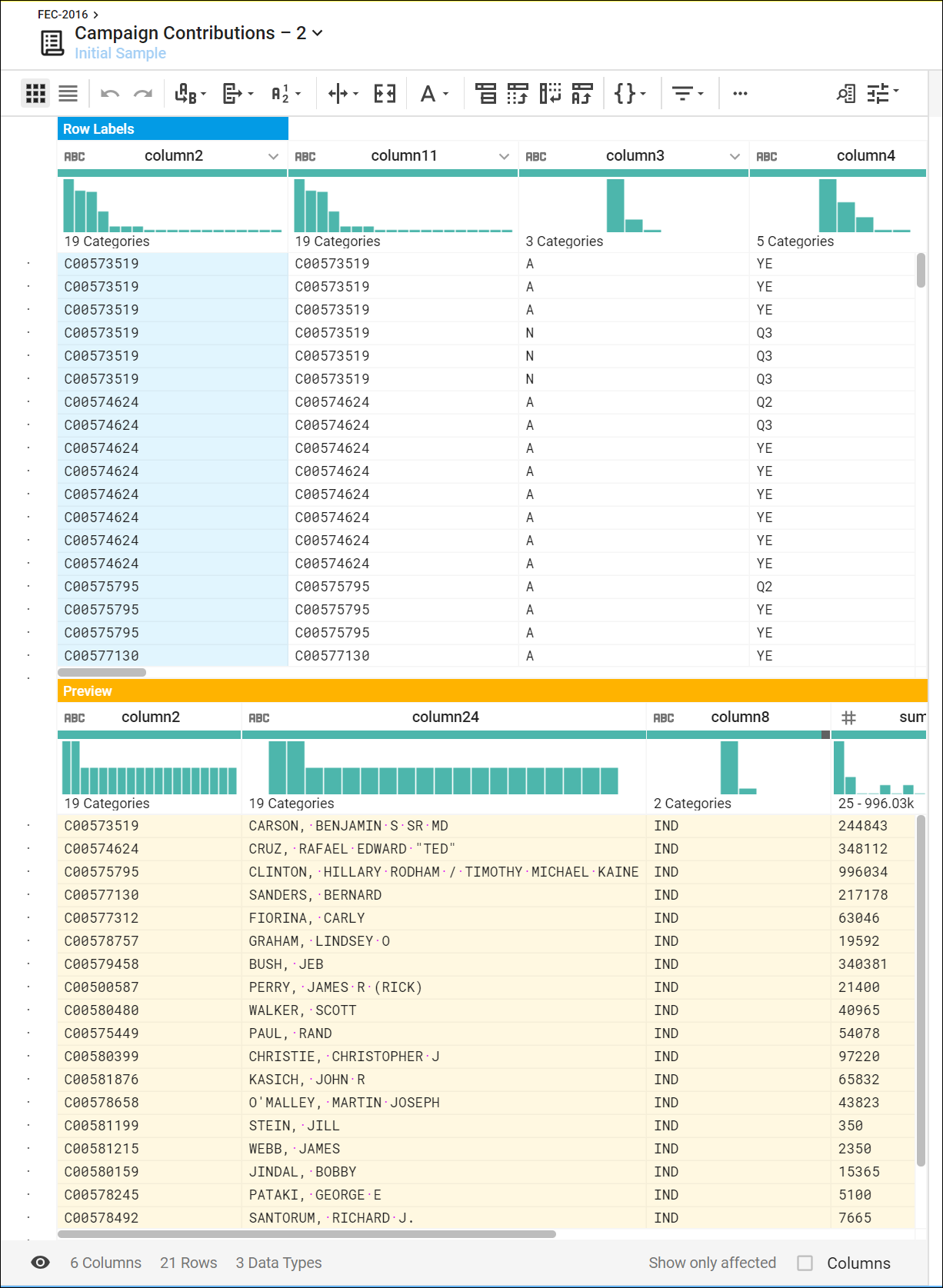
- [Add] をクリックして、主な米国大統領候補と、その 2016 年の選挙献金指標のサマリー テーブルを開きます。
タスク 8. 列名を変更する
列名を変更すると、データをさらに解析しやすくなります。
- そのためには、名前の変更と丸めの処理の各ステップをそれぞれレシピに追加します。[New Step] をクリックして以下を入力してください。
-
[Add] をクリックします。
-
平均献金額を丸めるには、次の行を [New Step] の末尾に貼り付けます。
- [Add] をクリックします。
結果は次のようになります。

お疲れさまでした
Dataprep を使用してデータセットを追加し、レシピを作成してデータを処理することで有意義な結果を導き出しました。
次のステップと詳細情報
このラボは、Google Cloud の多くの機能を体験できる「Qwik Start」と呼ばれるラボシリーズの一部です。ラボカタログで「Qwik Start」を検索し、興味のあるラボを探してみてください。
Google Cloud トレーニングと認定資格
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2023 年 9 月 15 日
ラボの最終テスト日: 2023 年 9 月 15 日
Copyright 2024 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。