Checkpoints
Create a new dataset
/ 25
Identify a key field in your ecommerce dataset
/ 25
Pitfall: non-unique key
/ 25
Join pitfall solution
/ 25
Desafios e solução de problemas da mesclagem de dados
- GSP412
- Informações gerais
- Configuração
- Tarefa 1. Crie um novo conjunto de dados para armazenar as tabelas
- Tarefa 2. Fixe o projeto do laboratório no BigQuery
- Tarefa 3. Examine os campos
- Tarefa 4. Identifique um campo chave no conjunto de dados de ecommerce
- Tarefa 5. Problema: chave não exclusiva
- Tarefa 6. Solução do problema de mesclagem: use SKUs diferentes antes de mesclar
- Parabéns!
GSP412

Informações gerais
O BigQuery é um banco de dados de análise NoOps, totalmente gerenciado e de baixo custo desenvolvido pelo Google. Com ele, você pode consultar muitos terabytes de dados sem ter que gerenciar uma infraestrutura ou precisar de um administrador de banco de dados. O BigQuery usa SQL e está disponível no modelo de pagamento por utilização. Assim, você pode se concentrar na análise dos dados para encontrar informações relevantes.
A mesclagem de tabelas de dados gera insights significativos sobre o conjunto de dados. No entanto, alguns problemas comuns podem corromper os resultados ao mesclar dados. Este laboratório explica como evitá-los. Tipos de mesclagem:
- Cross join (Correlação): combina cada uma das linhas do primeiro conjunto de dados com uma linha do segundo, e todas as combinações são representadas nos resultados.
- Inner join (Mesclagem interna): exige que as chaves-valor estejam em ambas as tabelas para que os registros sejam incluídos nos resultados. Esses registros só aparecerão na mesclagem se houver correspondências das chaves-valor nas duas tabelas.
- Left join (Mesclagem à esquerda): todas as linhas da tabela à esquerda aparecem nos resultados, mesmo sem correspondências à direita.
- Right join (Mesclagem à direita): é o contrário de uma mesclagem à esquerda. Todas as linhas da tabela à direita são incluídas nos resultados, mesmo que não haja correspondências à esquerda.
Para mais informações, consulte a página sobre mesclagens.
Você usará um conjunto de dados de comércio eletrônico com milhões de registros do Google Analytics referentes à Google Merchandise Store e carregados no BigQuery. Com uma cópia do conjunto de dados, você analisará os campos e linhas disponíveis para extrair insights.
Se você quiser informações sobre sintaxe para acompanhar e atualizar as consultas, consulte Sintaxe de consulta SQL padrão.
Atividades deste laboratório
Neste laboratório, você poderá:
- usar o BigQuery para explorar um conjunto de dados;
- remover linhas duplicadas em um conjunto de dados;
- criar mesclagens de tabelas de dados;
- entender cada tipo de mesclagem.
Configuração
Antes de clicar no botão Start Lab
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é iniciado quando você clica em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
- Tempo para concluir o laboratório---não se esqueça: depois de começar, não será possível pausar o laboratório.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar, você verá um pop-up para selecionar a forma de pagamento. No painel Detalhes do laboratório à esquerda, você verá o seguinte:
- O botão Abrir Console do Cloud
- Tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações se forem necessárias
-
Clique em Abrir Console do Google. O laboratório ativa recursos e depois abre outra guia com a página Fazer login.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta. -
Caso seja preciso, copie o Nome de usuário no painel Detalhes do laboratório e cole esse nome na caixa de diálogo Fazer login. Clique em Avançar.
-
Copie a Senha no painel Detalhes do laboratório e a cole na caixa de diálogo Olá. Clique em Avançar.
Importante: você precisa usar as credenciais do painel à esquerda. Não use suas credenciais do Google Cloud Ensina. Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais. -
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do GCP vai ser aberto nesta guia.

Abrir o console do BigQuery
- No Console do Google Cloud, selecione o menu de navegação > BigQuery:
Você verá a caixa de mensagem Olá! Este é o BigQuery no Console do Cloud. Ela tem um link para o guia de início rápido e as notas de versão.
- Clique em OK.
O console do BigQuery vai abrir.
Tarefa 1. Crie um novo conjunto de dados para armazenar as tabelas
No projeto do BigQuery, crie um novo conjunto de dados intitulado ecommerce.
- Clique nos três pontos ao lado do ID do projeto e selecione Criar conjunto de dados.
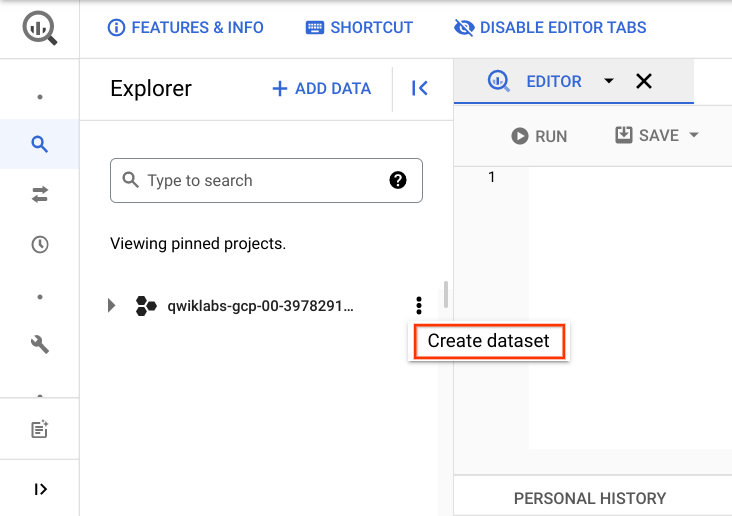
A caixa de diálogo Criar conjunto de dados será aberta.
-
Defina o ID do conjunto de dados como
ecommerce. -
Deixe as demais opções nos valores padrão e clique em Criar conjunto de dados.
No painel esquerdo, você verá uma tabela ecommerce relacionada no projeto.
Selecione Verificar meu progresso para conferir o objetivo.
Tarefa 2. Fixe o projeto do laboratório no BigQuery
Cenário: a equipe cria um novo conjunto de dados com os níveis de estoque de cada um dos produtos à venda no seu site de ecommerce. Conheça melhor os produtos do site e os campos que podem ser mesclados com outros conjuntos de dados.
O projeto com o novo conjunto de dados é chamado data-to-insights.
- Clique em Menu de navegação
> BigQuery.
A caixa de mensagem "Este é o BigQuery" vai aparecer no console do Cloud.
-
Clique em Concluído.
-
Por padrão, o BigQuery não mostra conjuntos de dados públicos. Para abrir o projeto contendo esse tipo de dados, copie data-to-insights.
-
Clique em + Adicionar > Marcar um projeto com estrela por nome e copie o nome "data-to-insights".
-
Clique em Marcar com estrela.
O projeto data-to-insights é listado na seção "Explorer".
Tarefa 3. Examine os campos
Em seguida, conheça melhor os produtos e campos do site para criar consultas e analisar o conjunto de dados.
-
No painel esquerdo, acesse a seção "Recursos" e navegue até
data-to-insights>ecommerce>all_sessions_raw. -
À direita, no "Editor de consultas", clique na guia Esquema para ver os campos e as informações sobre eles.
Tarefa 4. Identifique um campo chave no conjunto de dados de ecommerce
Examine os produtos e campos mais detalhadamente. Conheça melhor os produtos do site e os campos que podem ser mesclados com outros conjuntos de dados.
Analise os registros
Nesta seção, você verá quantos nomes e SKUs de produtos estão no site e se algum desses campos é exclusivo.
- Saiba quantos nomes e SKUs de produtos estão no site. Copie e cole a seguinte consulta no EDITOR do BigQuery:
- Clique em Executar.
Nos resultados de paginação no console, procure o número total de registros retornados.
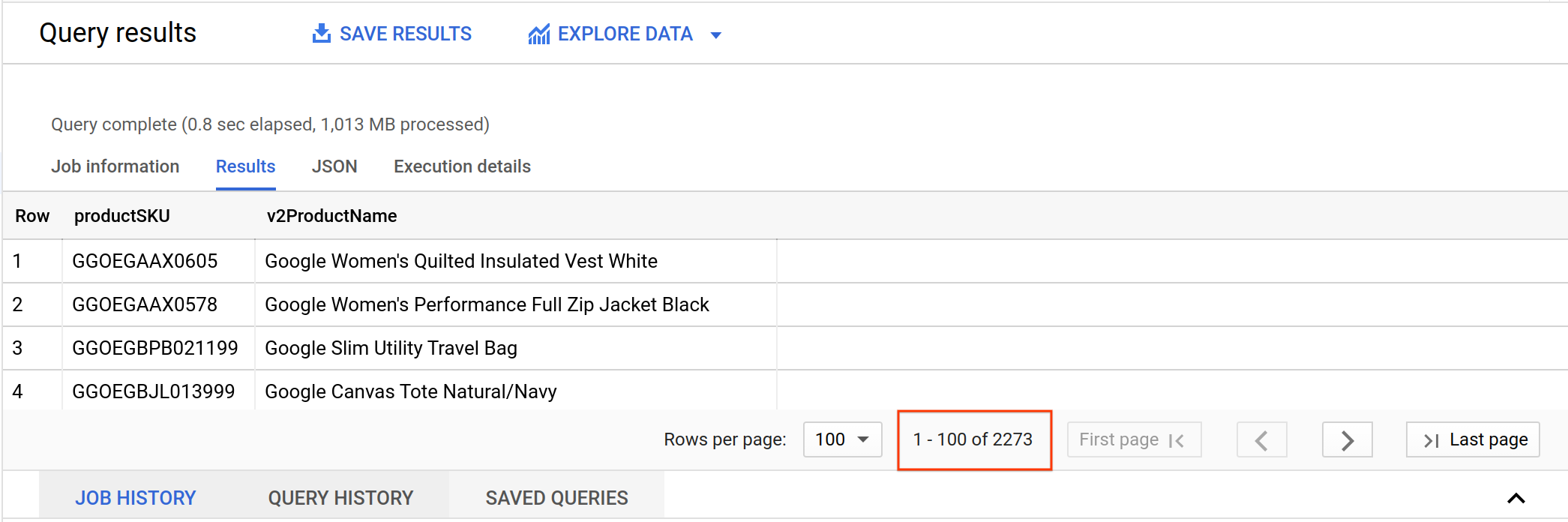
Será que esses resultados indicam que existem muitas SKUs exclusivas de produtos? Uma das primeiras consultas que você vai executar como analista de dados é observar a exclusividade dos valores dos dados.
- Limpe a consulta anterior e execute a consulta abaixo para listar o número de SKUs diferentes usando
DISTINCT:
Examine a relação entre SKU e nome
Agora, determine quais produtos têm mais de uma SKU e quais SKUs têm mais de um nome de produto.
- Limpe a consulta anterior e execute a consulta abaixo para determinar se há nomes do produto com mais de uma SKU. A função STRING_AGG() é usada para agregar todas as SKUs de produto associadas a um nome de produto em valores separados por vírgulas.
- Clique em Executar.
Resultados:
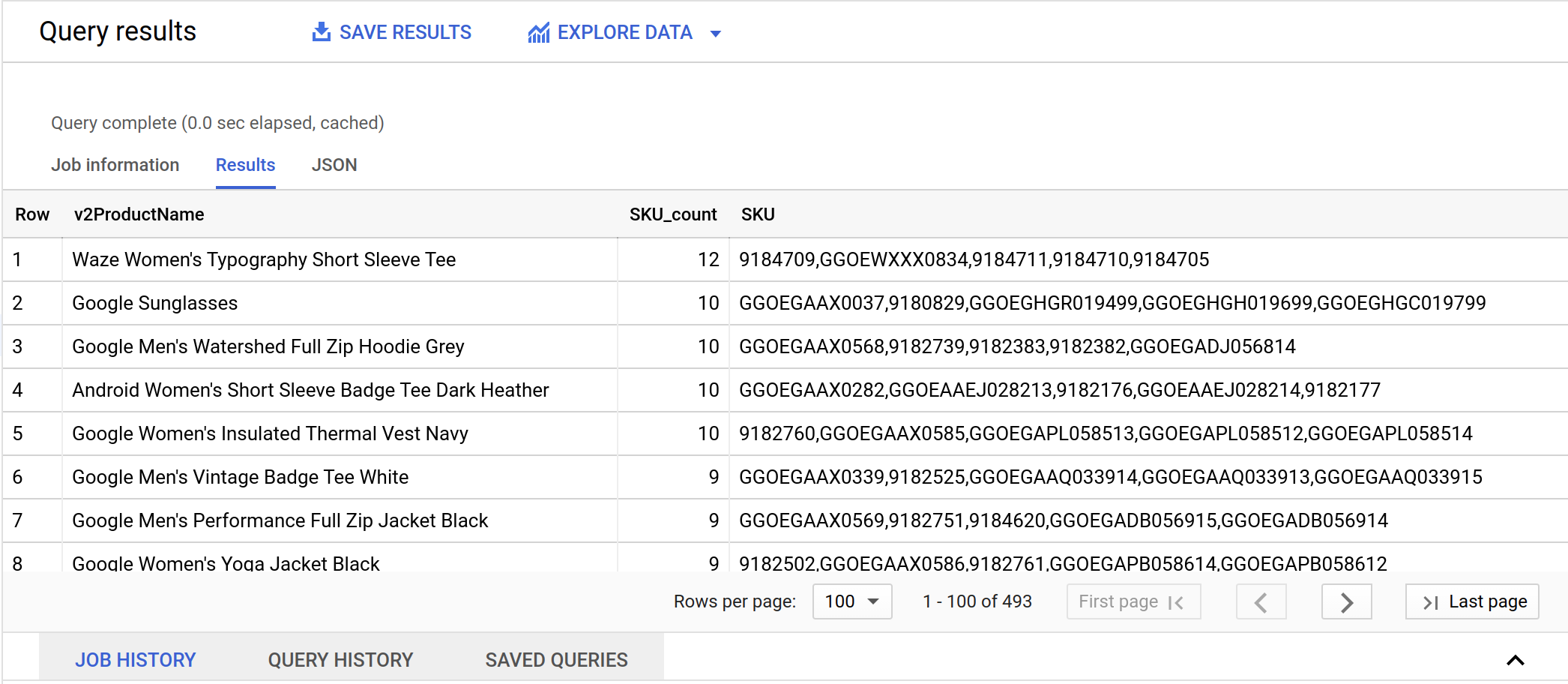
O catálogo de sites de ecommerce mostra que cada nome de produto pode ter diversas opções (como tamanho e cor), que são vendidas como SKUs separados.
Então você percebeu que um produto pode ter 12 SKUs. E quanto a um SKU? Pode pertencer a mais de um produto?
- Limpe a consulta anterior e execute a consulta abaixo para descobrir:
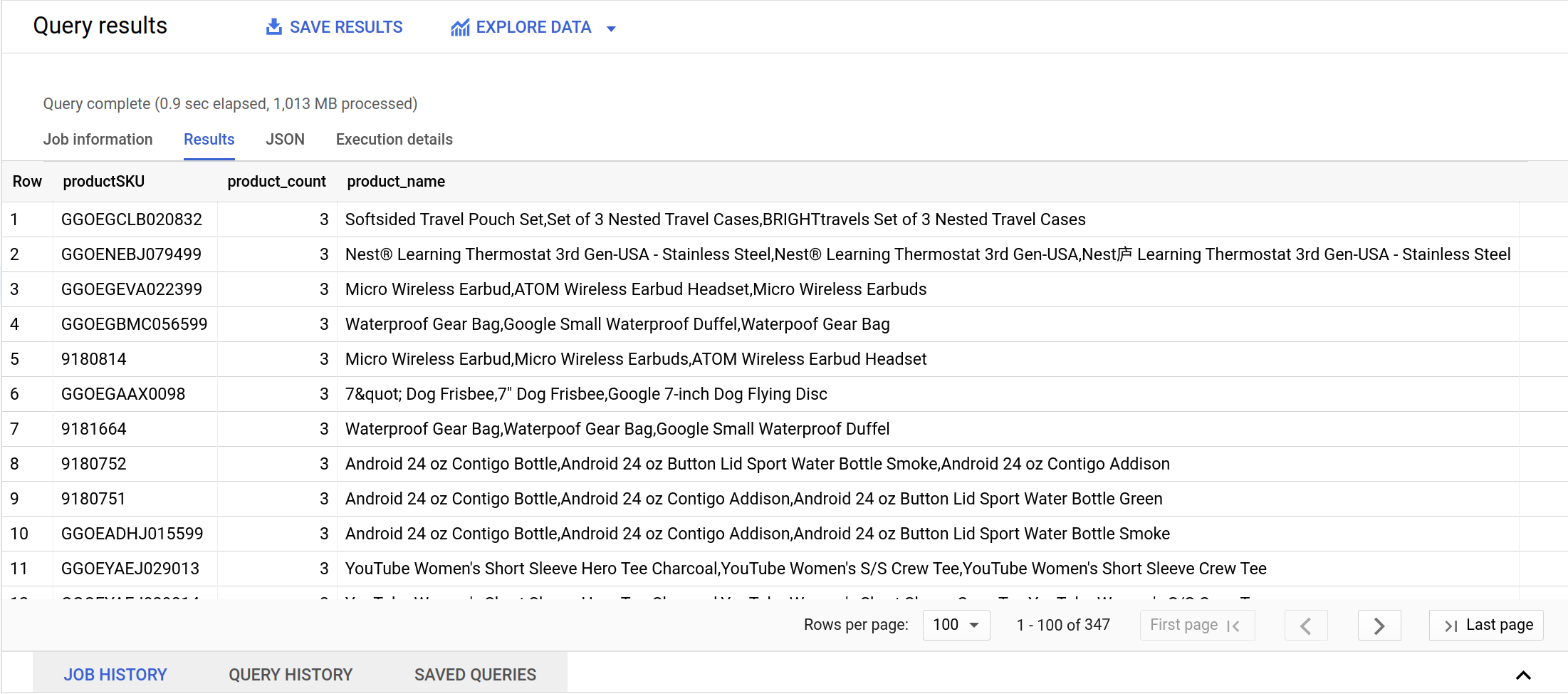
Na próxima seção, você vai entender por que esse relacionamento de dados de muitos para muitos é um problema.
Selecione Verificar meu progresso para conferir o objetivo.
Tarefa 5. Problema: chave não exclusiva
No rastreamento de estoque, as SKUs foram feitas para identificar cada produto de maneira exclusiva. Para nós, serão a base da condição JOIN ao pesquisar informações de outras tabelas. Como vamos estudar em breve, a presença de uma chave não exclusiva pode causar sérios problemas aos dados.
-
Crie uma consulta para identificar todos os nomes de produtos referentes à SKU
'GGOEGPJC019099'.
Possível solução:
- Clique em Executar.
|
v2ProductName |
productSKU |
|
7" Dog Frisbee |
GGOEGPJC019099 |
|
7" Dog Frisbee |
GGOEGPJC019099 |
|
Google 7-inch Dog Flying Disc Blue |
GGOEGPJC019099 |
Nos resultados da consulta, parece que há três nomes diferentes para o mesmo produto. No exemplo, um dos nomes tem um caractere especial, e o outro é um pouco diferente dos demais:
Como mesclar dados do site à lista de inventário de produtos
Observe o impacto de mesclar um conjunto de dados com vários produtos da mesma SKU. Primeiro, confira o conjunto de dados do inventário de produtos (a tabela de produtos) para saber se a SKU é exclusiva.
- Limpe a consulta anterior e execute a consulta abaixo:
Problema de mesclagem: relação não intencional de muitas SKUs para uma
Agora você tem dois conjuntos de dados: um para o nível de estoque e outro para análises do nosso site. Use JOIN no conjunto de dados do inventário de nomes de produtos e SKUs do site para ter o nível de estoque associado a cada produto à venda no site.
- Limpe a consulta anterior e execute a consulta abaixo:
Em seguida, expanda a consulta anterior para aplicar SUM (soma) ao estoque disponível por produto.
- Limpe a consulta anterior e execute a consulta abaixo:
Ah, não! O resultado é 154 x 3 = 462 ou contagem tripla do inventário. Isso é chamado de correlação não intencional (um tópico que vamos revisar mais tarde).
Selecione Verificar meu progresso para conferir o objetivo.
Tarefa 6. Solução do problema de mesclagem: use SKUs diferentes antes de mesclar
Quais são as opções para resolver o dilema da contagem tripla? Primeiro, é preciso selecionar apenas SKUs distintas do site antes de mesclar a outros conjuntos de dados.
Pode haver mais de um nome de produto (como 7" Dog Frisbee) compartilhando um único SKU.
- Reúna todos os nomes possíveis em uma matriz:
Agora, em vez de ter uma linha para cada nome de produto, você terá apenas uma linha para cada SKU exclusiva.
- Se você quiser eliminar a duplicação dos nomes dos produtos, limite a matriz assim:
Problema de mesclagem: perda de registros de dados após uma mesclagem
Agora está tudo pronto para mesclar o conjunto de dados do inventário de produtos novamente.
- Limpe a consulta anterior e execute a consulta abaixo:
Parece que 819 SKUs foram perdidas após a mesclagem dos conjuntos de dados. Investigue adicionando mais detalhes nos campos (uma coluna SKU de cada conjunto de dados):
- Limpe a consulta anterior e execute a consulta abaixo:
Parece que as SKUs estão nos dois conjuntos de dados após a mesclagem dos 1.090 registros. Como encontrar os registros perdidos?
Solução do problema da mesclagem: selecione o tipo de mesclagem correto e filtre por NULL
O tipo padrão de JOIN é o INNER JOIN que retorna registros somente se houver uma correspondência nas tabelas à esquerda e à direita que foram mescladas.
- Reescreva a consulta anterior para usar um outro tipo de mesclagem que inclua todos os registros da tabela do site, independentemente de haver correspondência no registro de SKU do inventário de produtos. As opções de tipo de mesclagem são: INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN e CROSS JOIN.
Possível solução:
- Clique em Executar.
Você usou LEFT JOIN para retornar todas as 1.909 SKUs originais do site nos resultados.
Quantas SKUs faltam no conjunto de inventário de produtos?
- Escreva uma consulta para filtrar os valores NULL da tabela de inventário.
Possível solução:
- Clique em Executar.
Pergunta: quantos produtos faltam?
Resposta: 819 produtos estão faltando (SKU IS NULL) no conjunto de dados do inventário de produtos.
- Limpe a consulta anterior e execute a consulta abaixo para confirmar o uso de uma das SKUs específicas do conjunto de dados do site:
E o contrário? Há algum produto no conjunto de dados do inventário de produtos que não está no site?
- Escreva uma consulta usando um outro tipo de mesclagem para investigar.
Possível solução:
- Clique em Executar.
Resposta: sim. Faltam duas SKUs de produto no conjunto de dados do site.
Em seguida, adicione mais campos do conjunto de dados do inventário de produtos para saber mais detalhes.
- Limpe a consulta anterior e execute a consulta abaixo:
Por que os produtos abaixo estão faltando no conjunto de dados do site de ecommerce?
|
website_SKU |
SKU |
name |
orderedQuantity |
stockLevel |
restockingLeadTime |
sentimentScore |
sentimentMagnitude |
|
null |
GGOBJGOWUSG69402 |
USB wired soundbar - in store only |
10 |
15 |
2 |
1.0 |
1.0 |
|
null |
GGADFBSBKS42347 |
PC gaming speakers |
0 |
100 |
1 |
null |
null |
Possíveis respostas:
- Um deles é um novo produto (não há pedidos ou "sentimentScore") e está disponível "somente na loja" (in store only).
- O outro é um novo produto com "0" pedidos.
Por que os novos produtos não aparecem no conjunto de dados do site?
- O conjunto de dados do site contém transações de clientes de pedidos anteriores. Os produtos novos que nunca foram vendidos não serão exibidos na análise da Web até que sejam visualizados ou comprados.
E se você quisesse uma consulta que listasse todos os produtos que não constam no site ou no inventário?
- Escreva uma consulta usando um outro tipo de mesclagem.
Possível solução:
- Clique em Executar.
Você tem 819 + 2 = 821 SKUs.
LEFT JOIN + RIGHT JOIN = FULL JOIN de produtos, que retorna todos os registros de ambas as tabelas, sem depender das chaves de mesclagem correspondentes. Depois, basta filtrar as instâncias sem correspondência em um dos lados.
Problema de mesclagem: correlação não intencional
Não saber a relação entre as chaves das tabelas de dados (1:1, 1:N, N:N) pode gerar resultados inesperados, além de prejudicar significativamente o desempenho da consulta.
O último tipo de mesclagem é a CORRELAÇÃO.
Crie uma nova tabela com a porcentagem de desconto que você quer aplicar em todo o site nos produtos da categoria "Promoção".
- Limpe a consulta anterior e execute a consulta abaixo:
No painel à esquerda, agora está listado o site_wide_promotion, na seção "Recursos" do projeto e conjunto de dados.
- Limpe a consulta anterior e execute a consulta abaixo para encontrar a quantidade de produtos em liberação:
Acompanhe o impacto da adição não intencional de mais de um registro na tabela de descontos.
- Limpe a consulta anterior e execute a consulta abaixo para inserir mais dois registros na tabela de promoção:
Agora, vamos conferir os valores de dados na tabela de promoção.
- Limpe a consulta anterior e execute a consulta abaixo:
Quantos registros foram retornados?
Resposta: 3
O que acontece se você aplica o desconto novamente em todos os 82 produtos em promoção?
- Limpe a consulta anterior e execute a consulta abaixo:
Quantos produtos foram retornados?
Resposta: em vez de 82, retornou 246. São muito mais registros do que havia na tabela inicial.
Para investigar a causa subjacente, analise uma SKU de produto.
- Limpe a consulta anterior e execute a consulta abaixo:
Qual foi o impacto da CROSS JOIN?
Resposta: como existem três códigos de desconto para correlacionar, o conjunto de dados original é multiplicado por 3.
A solução é conhecer as relações de dados antes da mesclagem e não presumir que as chaves são exclusivas.
Selecione Verificar meu progresso para conferir o objetivo.
Parabéns!
Você concluiu este laboratório e lidou com alguns problemas sérios da mesclagem de SQL ao identificar registros duplicados e reconhecer quando usar cada tipo de JOIN. Bom trabalho!
Termine a Quest
Este laboratório autoguiado faz parte da Quest BigQuery for Data Warehousing. Uma Quest é uma série de laboratórios relacionados que formam um programa de aprendizado. Ao concluir uma Quest, você ganha um selo como reconhecimento da sua conquista. É possível publicar os selos e incluir um link para eles no seu currículo on-line ou nas redes sociais. Se você já fez este laboratório, inscreva-se nesta Quest para receber os créditos de conclusão imediatamente. Consulte o catálogo do Google Cloud Ensina para ver todas as Quests disponíveis.
Comece o próximo laboratório
Continue sua Quest com outro laboratório, como Working with JSON, Arrays, and Structs in BigQuery, ou confira estas sugestões:
- Introdução ao SQL para BigQuery e Cloud SQL
- Estimar tarifas de táxi com um modelo de previsão do BigQuery ML
Próximas etapas / Saiba mais
-
Você já tem uma conta do Google Analytics e quer consultar seus próprios conjuntos de dados no BigQuery? Siga este guia de exportação.
-
Conheça as práticas recomendadas sobre como otimizar a computação em consultas.
-
Se você quiser praticar mais a sintaxe SQL de mesclagem com JOIN, confira a documentação sobre JOIN no BigQuery.
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em: 10 de maio de 2023
Teste mais recente do laboratório: 10 de maio de 2023
Copyright 2024 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.